Este material apresenta conceitos essenciais de análise de dados, incluindo histogramas, visualização de distribuições e relações entre variáveis.
Começamos criando um conjunto de dados sintéticos que segue uma distribuição normal. Isso será útil para entender como visualizar distribuições antes de analisarmos dados reais.
Importanto das bibliotecas.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import randomdef gaussian_random_walk(num_steps,num_amostras):
"""Generates a Gaussian distribution using a random walk."""
final_position = []
for i in range(num_amostras):
position = 0
for _ in range(num_steps):
step = random.choice([-1, 1]) # Choose -1 or 1 with equal probability
position += step
final_position.append(position)
return final_position
# Example usage: generate a random walk with 1000 steps
num_steps = 200
num_amostras = 10000
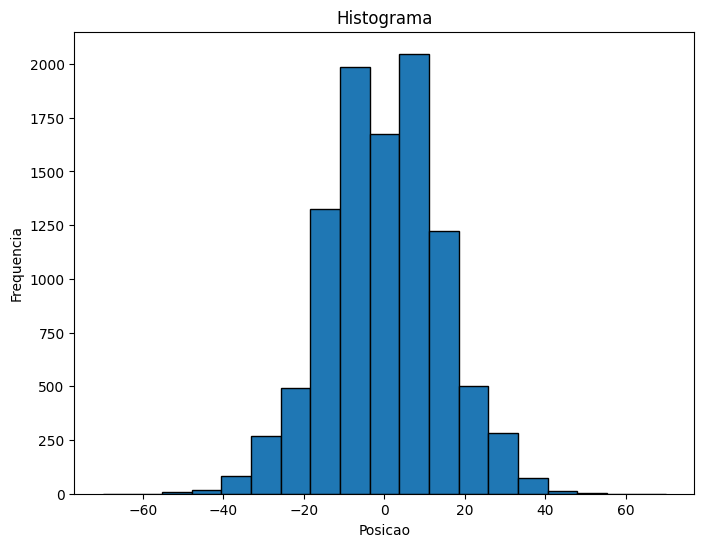
final_position = gaussian_random_walk(num_steps,num_amostras)O código abaixo gera um histograma de frequencias (nao normalizado) a partir dos dados e exibe a distribuição dos valores.
plt.figure(figsize=(8, 6))
freq, bins = np.histogram(final_position, bins=np.linspace(-70,70,20))
bin_centers = (bins[:-1] + bins[1:]) / 2 # Calculate bin centers
plt.bar(bin_centers, freq, width=np.diff(bins), align='center',edgecolor="black")
plt.xlabel("Posicao")
plt.ylabel("Frequencia")
plt.title("Histograma")
plt.show()
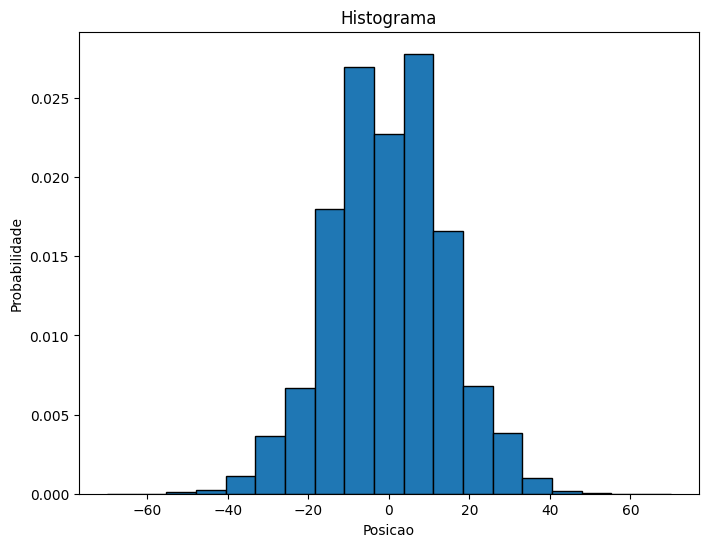
O código abaixo gera um histogram *normalizado* a a partir dos dados e exibe a distribuição dos valores.
plt.figure(figsize=(8, 6))
freq, bins = np.histogram(final_position, bins=np.linspace(-70,70,20),density="True")
bin_centers = (bins[:-1] + bins[1:]) / 2 # Calculate bin centers
plt.bar(bin_centers, freq, width=np.diff(bins), align='center',edgecolor="black")
plt.xlabel("Posicao")
plt.ylabel("Probabilidade")
plt.title("Histograma")
plt.show()
Este trecho de código carrega um conjunto de dados reais a partir de um arquivo CSV.
def load_data(file_path):
"""Carrega o arquivo CSV e corrige os nomes das colunas."""
df = pd.read_csv(file_path)
df.columns = df.columns.str.strip()
df["State"] = df["State"].str.strip()
return df
# Exemplo de uso:
df = load_data('pone.0223059.s002.csv')Filtramos os dados para selecionar apenas informações de um estado específico.
def filter_state(df, state):
"""Filtra os dados para um estado específico."""
return df[df["State"] == state].copy()
# Exemplo de uso:
df_sp = filter_state(df, 'SP')
# Remove rows where both 'Money (R$ Reais)' and 'Votes' are zero
df_sp = df_sp[(df_sp['Money (R$ Reais)'] > 0)]
df_sp = df_sp[df_sp['Votes'] > 0]
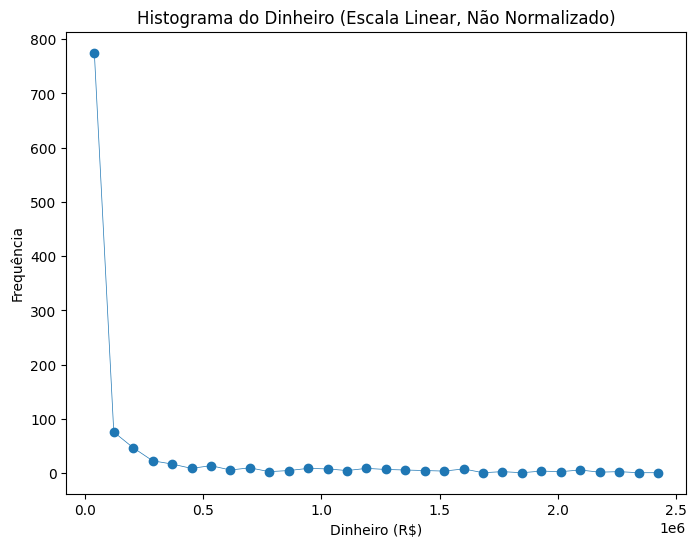
df_spO código abaixo gera um histograma a partir dos dados e exibe a distribuição dos valores.
plt.figure(figsize=(8, 6))
freq,bins = np.histogram(df_sp["Money (R$ Reais)"], bins=30)
bin_centers = (bins[:-1] + bins[1:]) / 2 # Calculate bin centers
plt.xlabel("Dinheiro (R$)")
plt.ylabel("Frequência")
plt.title("Histograma do Dinheiro (Escala Linear, Não Normalizado)")
plt.plot(bin_centers, freq, "o-", linewidth=0.5)
plt.show()
O código abaixo gera um histograma a partir dos dados e exibe a distribuição dos valores.
plt.figure(figsize=(8, 6))
freq,bins = np.histogram(df_sp["Money (R$ Reais)"], bins=30)
bin_centers = (bins[:-1] + bins[1:]) / 2 # Calculate bin centers
plt.xlabel("Dinheiro (R$)")
plt.ylabel("Frequência")
plt.title("Histograma do Dinheiro (Escala LogLog, Não Normalizado)")
plt.loglog()
plt.plot(bin_centers, freq, "o-", linewidth=0.5)
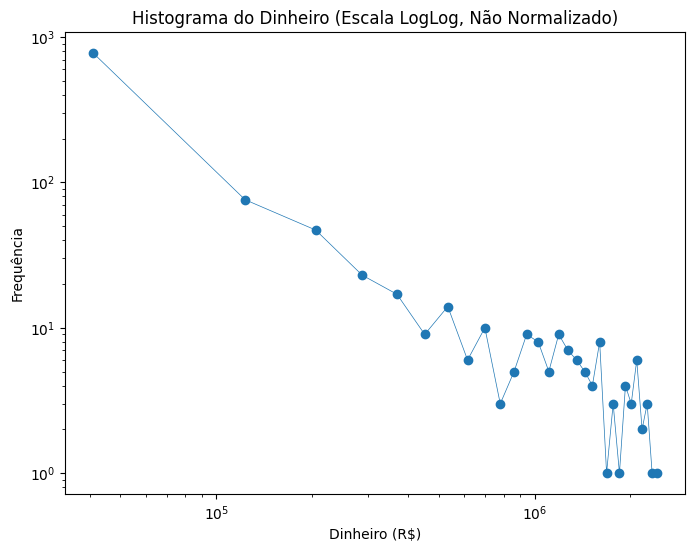
O código abaixo gera um histograma a partir dos dados e exibe a distribuição dos valores.
plt.figure(figsize=(8, 6))
freq,bins = np.histogram(df_sp["Votes"], bins=100)
bin_centers = (bins[:-1] + bins[1:]) / 2 # Calculate bin centers
plt.xlabel("votos")
plt.ylabel("Frequência")
plt.title("Histograma dos Votos (Escala LogLog, Não Normalizado)")
plt.loglog()
plt.plot(bin_centers, freq, "o-", linewidth=0.5)
plt.show()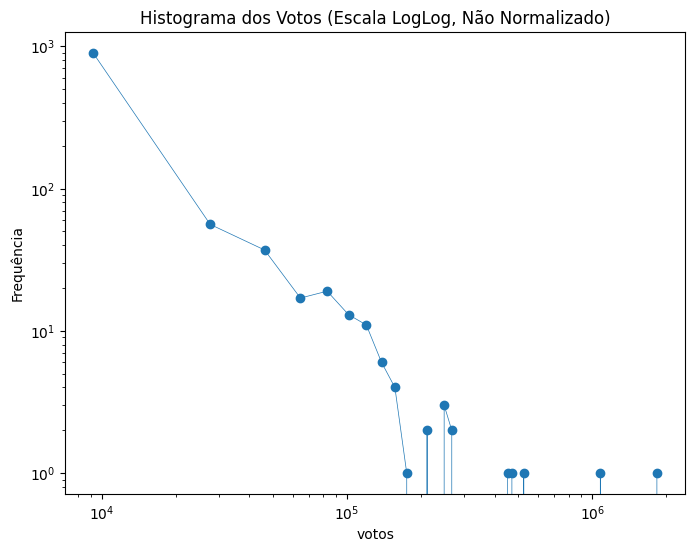
plt.figure(figsize=(8, 6))
freq_lin,bins_lin = np.histogram(df_sp["Votes"], bins = 30)
freq,bins = np.histogram(df_sp["Votes"], bins=np.logspace(np.log10(df_sp["Votes"].min()), np.log10(df_sp["Votes"].max()), 30))
bin_centers = (bins[:-1] + bins[1:]) / 2 # Calculate bin centers
plt.xlabel("votos")
plt.ylabel("Frequência")
plt.title("Histograma dos Votos (Escala LogLog, Não Normalizado)")
plt.loglog()
plt.plot(bin_centers, freq, "o-", linewidth=0.5,label="log")
plt.plot((bins_lin[:-1] + bins_lin[1:]) / 2, freq_lin, "ro-", linewidth=0.5,label="linear")
plt.legend()
plt.show()
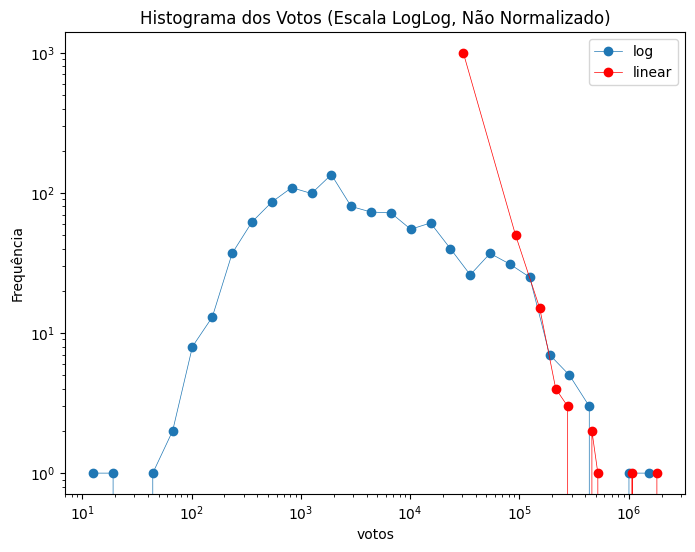
Este código plota um gráfico de dispersão para visualizar a relação entre duas variáveis.
plt.figure(figsize=(8, 6))
plt.scatter(df_sp["Money (R$ Reais)"], df_sp["Votes"], alpha=0.3)
plt.xscale("log")
plt.yscale("log")
plt.xlabel("Dinheiro (R$) [Escala Log]")
plt.ylabel("Votos [Escala Log]")
plt.title("Scatter Plot de Votos vs. Dinheiro")
#plt.grid(True, which="both", linestyle="--", linewidth=0.5)
plt.show()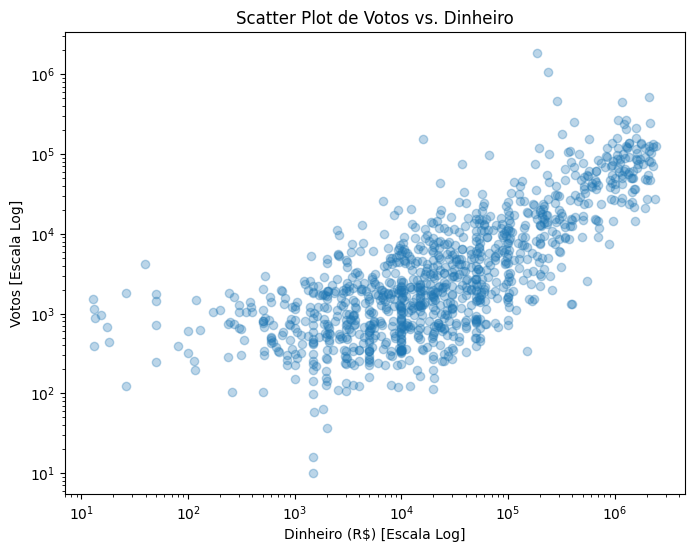
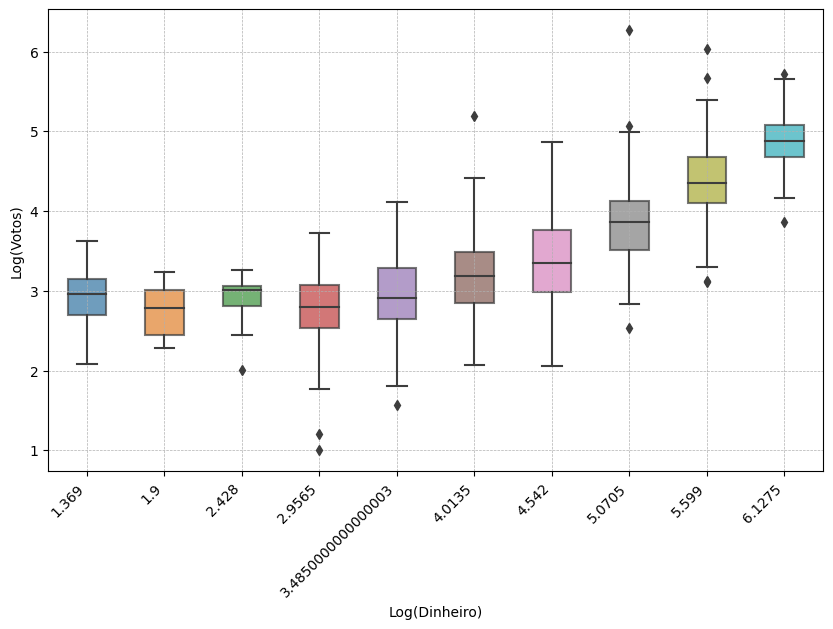
Aqui geramos um box plot, que nos ajuda a identificar a distribuição e possíveis outliers nos dados.
df_sp["Log Money"] = np.log10(df_sp["Money (R$ Reais)"])
df_sp["Log Votes"] = np.log10(df_sp["Votes"])
df_sp["Log Money Bin"] = pd.cut(df_sp["Log Money"], bins=10)
plt.figure(figsize=(10, 6))
sns.boxplot(x=df_sp["Log Money Bin"].map(lambda x: x.mid if pd.notna(x) else np.nan), y=df_sp["Log Votes"], width=0.5, showfliers=True, boxprops=dict(alpha=0.7))
plt.xticks(rotation=45, ha="right")
plt.xlabel("Log(Dinheiro)")
plt.ylabel("Log(Votos)")
plt.grid(True, linestyle="--", linewidth=0.5)
plt.show()