Mude o valor de `size` para 30, 50 ou 100 e observe o que acontece.
Rode a célula várias vezes e veja como os valores mudam.
Parte 2 – Medidas de Dispersão com Dados Simulados
Agora vamos calcular:
Variância
Desvio padrão
Coeficiente de variação (CV)
# Medidas de dispersão
variancia = np.var(dados, ddof=1) # ddof=1 para amostra
desvio_padrao = np.std(dados, ddof=1)
coef_var = desvio_padrao / media
print(f"Variância: {variancia:.2f}")
print(f"Desvio padrão: {desvio_padrao:.2f}")
print(f"Coeficiente de variação: {coef_var:.2%}")
Variância: 52.27
Desvio padrão: 7.23
Coeficiente de variação: 13.27%
Parte 3 – Usando Dados Reais: População das Cidades Brasileiras
Nesta etapa, vamos usar um dataset com dados reais de população das cidades brasileiras. Calcule as mesmas medidas de tendência central e dispersão.
# Leitura correta do CSV com header na linha 2
import pandas as pd
import matplotlib.pyplot as plt
arquivo = 'ipeadata[31-03-2025-03-06].csv'
df = pd.read_csv(arquivo, header=1)
df.head()
Sigla Código Município 2000 2007 2010 2022 Unnamed: 7
0 AC 1200013 Acrelândia 7935.0 11520.0 12538.0 14021.0 NaN
1 AC 1200054 Assis Brasil 3490.0 5351.0 6072.0 8100.0 NaN
2 AC 1200104 Brasiléia 17013.0 19065.0 21398.0 26000.0 NaN
3 AC 1200138 Bujari 5826.0 6543.0 8471.0 12917.0 NaN
4 AC 1200179 Capixaba 5206.0 8446.0 8798.0 10392.0 NaN
# Selecionar e limpar os dados de população de 2022
pop_2022 = df['2022'].dropna()
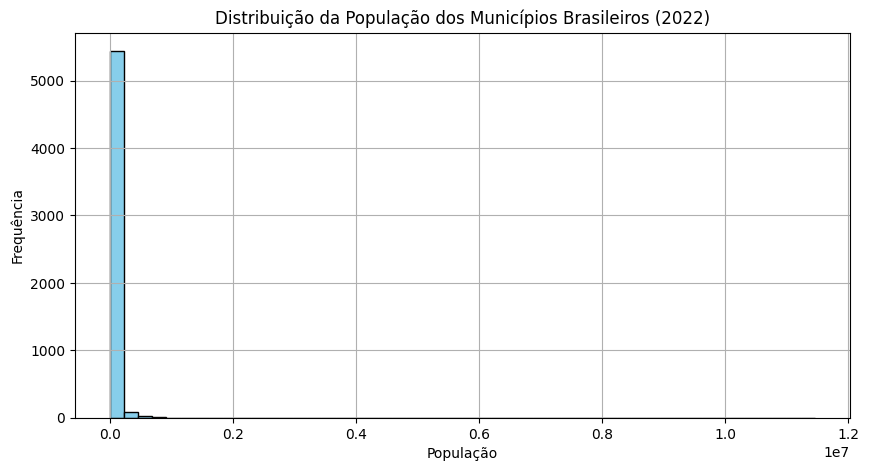
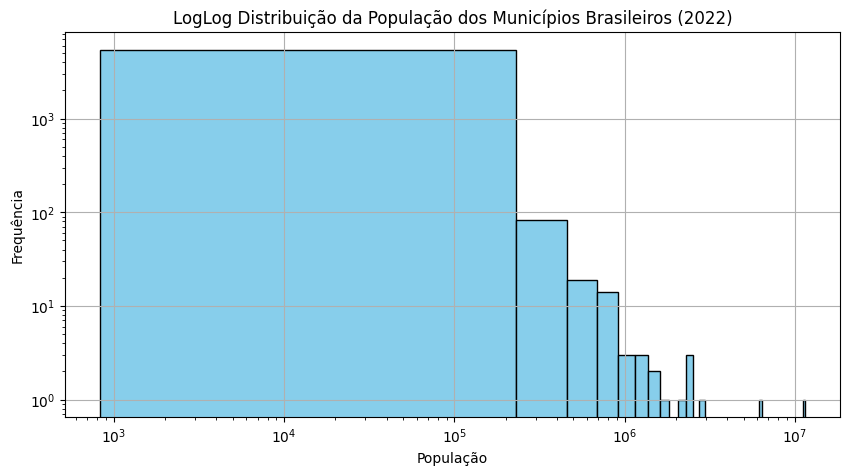
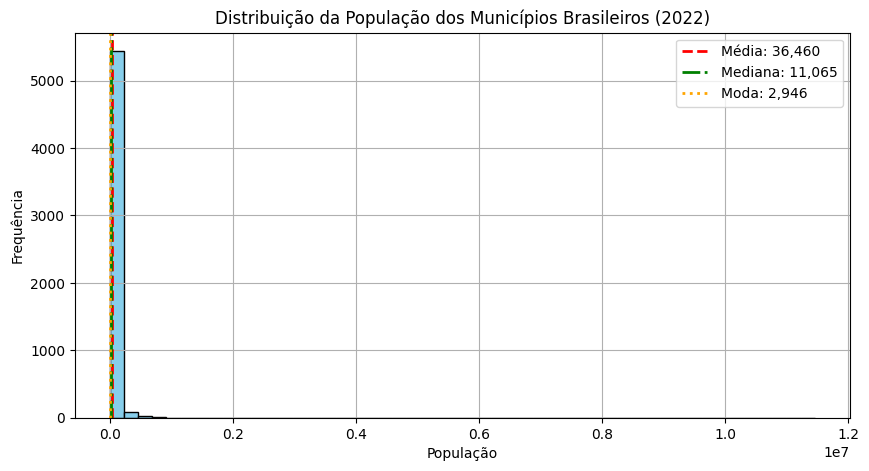
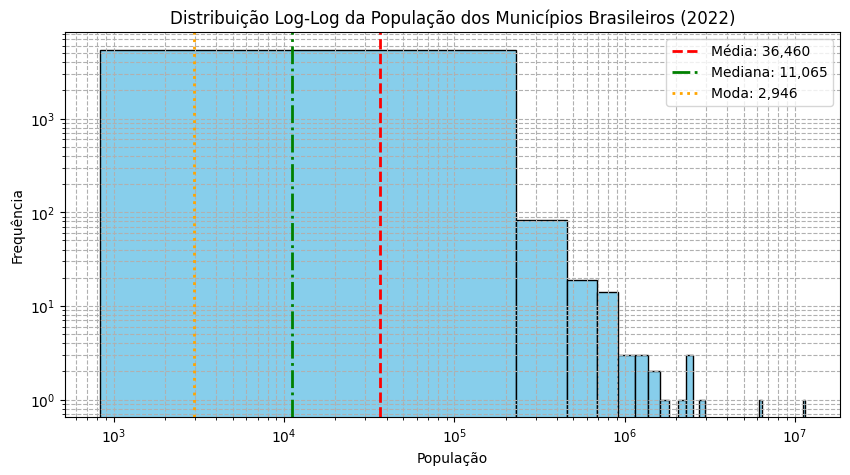
print(f"Total de municípios: {len(pop_2022)}")
pop_2022.describe()
Total de municípios: 5570
count 5.570000e+03
mean 3.645974e+04
std 2.065187e+05
min 8.330000e+02
25% 5.228000e+03
50% 1.106500e+04
75% 2.442725e+04
max 1.145200e+07
Name: 2022, dtype: float64
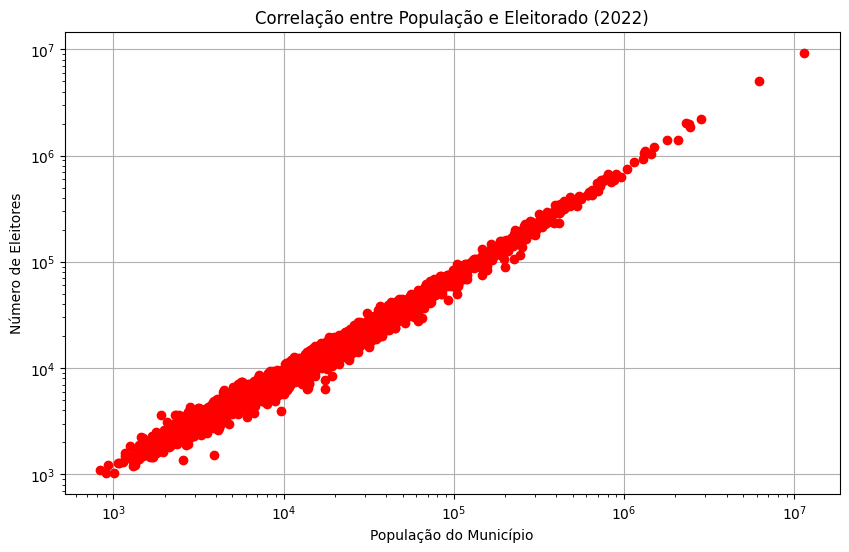
# Cálculo da covariância e correlação
cov = df_merged['Populacao'].cov(df_merged['Eleitorado'])
corr = df_merged['Populacao'].corr(df_merged['Eleitorado'])
print(f"Covariância: {cov:,.2f}")
print(f"Coeficiente de correlação de Pearson: {corr:.4f}")
Covariância: 33,960,675,818.86
Coeficiente de correlação de Pearson: 0.9986
# Gráfico de dispersão com linha de tendência
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 6))
#sns.regplot(data=df_merged, x='Populacao', y='Eleitorado', scatter_kws={'alpha':0.5})
plt.plot(df_merged.Populacao,df_merged.Eleitorado,"ro")
#plt.plot(np.linspace(100,1e7),np.linspace(100,1e7),"--")
plt.title('Correlação entre População e Eleitorado (2022)')
plt.xlabel('População do Município')
plt.ylabel('Número de Eleitores')
plt.loglog()
plt.grid(True)
plt.show()