Nesta aula, vamos revisar passo a passo os conceitos e a aplicação dos testes de hipótese: executar testes Z, testes t, calcular p-valores e aplicar o teste qui-quadrado.
1. O que é um Teste de Hipótese?
Um teste de hipótese é uma técnica estatística usada para avaliar se há evidência suficiente nos dados para rejeitar uma hipótese inicial (nula), a favor de uma alternativa.
2. Etapas de um Teste de Hipótese
1. Formular H₀ e H₁
2. Escolher o teste (Z, t, χ²)
3. Executar o teste
4. Tomar decisão com base em valor crítico ou p-valor
3. Formulação de Hipóteses
Exemplo:
H₀: O salário médio é 113k
H₁: O salário médio é diferente de 113k (bilateral)
4. Testes Unilaterais e Bilaterais
Teste bilateral: H₁ ≠ H₀
Teste unilateral: H₁ > H₀ ou H₁ < H₀
5. Nível de Significância (α)
É a probabilidade de rejeitar H₀ quando ela é verdadeira.
Valor típico: α = 0.05 (5%).
6. Valor Crítico vs p-valor
Valor crítico: limite da região de rejeição
p-valor: menor nível de significância compatível com o resultado
Se p < α → rejeita-se H₀
7. Erros Tipo I e Tipo II
Erro tipo I (α): rejeitar H₀ quando ela é verdadeira
Erro tipo II (β): não rejeitar H₀ quando ela é falsa
Poder do teste = 1 - β
8. Exemplo Prático – Teste Z
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
mu0 = 113000
sigma = 10000
n = 30
#np.random.seed(0)
amostra = np.random.normal(loc=115000, scale=sigma, size=n)
media = np.mean(amostra)
z = (media - mu0) / (sigma / np.sqrt(n))
alpha = 0.05
z_crit = norm.ppf(1-alpha/2.)
print(f"Estatística Z: {z:.2f}")
print(f"Valor crítico: {z_crit:.2f}")
if abs(z) > z_crit:
print("Rejeitamos H₀")
else:
print("Não rejeitamos H₀")
Estatística Z: 0.55
Valor crítico: 1.96
Não rejeitamos H₀
Se repetir esse experimento milhares de vezes, quantas vezes a hipotese sera rejeitada? quantas seram aceita?
9. Exemplo Prático – Teste t (σ desconhecido)
from scipy.stats import t
amostra = [26, 23, 42, 49, 23, 59, 29, 29, 57, 40]#np.random.normal(loc=115000, scale=sigma, size=n)
# Amotra de 8 porcentagens de abertura de emails - segundo exemplo da aula teorica.
mu0 = 40
#h0 = A media de abertura do concorrente é menor que a sua (40%)
#h1 = A taxa de abertura é maior que 40%
# Portanto é um teste unilateral...
s = np.std(amostra, ddof=1)
media = np.mean(amostra)
n = len(amostra)
print("media: ",media)
t_stat = (media - mu0) / (s / np.sqrt(n))
df = n - 1
alpha = 0.05
t_crit = t.ppf(1-alpha, df)
print(f"Estatística t: {t_stat:.2f}")
print(f"Valor crítico (t): ±{t_crit:.2f}")
if abs(t_stat) > t_crit:
print("Rejeitamos H₀")
else:
print("Não rejeitamos H₀ / Aceitamos H0")
media: 37.7
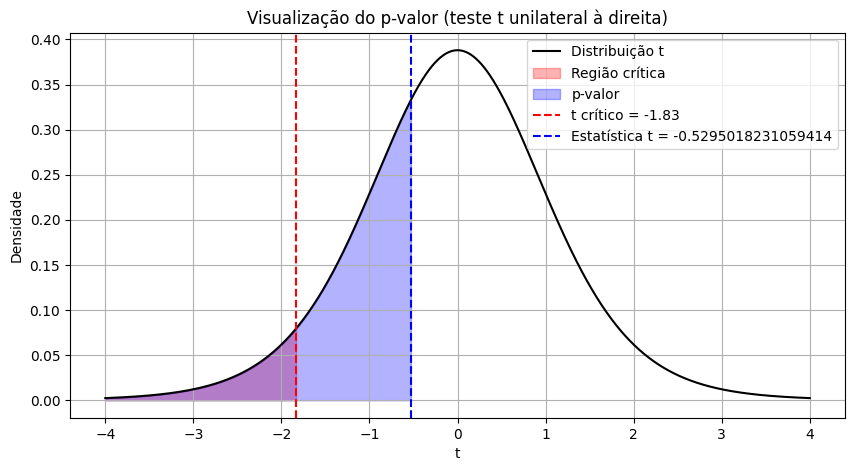
Estatística t: -0.53
Valor crítico (t): ±1.83
Não rejeitamos H₀ / Aceitamos H0
# Parâmetros
df = n-1
alpha = 0.05
# Eixo x e densidade t
x = np.linspace(-4, 4, 1000)
y = t.pdf(x, df)
# Valor crítico
t_crit = t.ppf(alpha, df)
# Plot
plt.figure(figsize=(10, 5))
plt.plot(x, y, label='Distribuição t', color='black')
# Região crítica
x_rej = np.linspace(-4, t_crit, 300)
plt.fill_between(x_rej, t.pdf(x_rej, df), color='red', alpha=0.3, label='Região crítica')
# p-valor (à direita de t observado)
x_p = np.linspace(-4, t_stat, 300)
plt.fill_between(x_p, t.pdf(x_p, df), color='blue', alpha=0.3, label='p-valor')
# Linhas verticais
plt.axvline(t_crit, color='red', linestyle='--', label=f't crítico = {t_crit:.2f}')
plt.axvline(t_stat, color='blue', linestyle='--', label=f'Estatística t = {t_stat}')
# Decoração
plt.title("Visualização do p-valor (teste t unilateral à direita)")
plt.xlabel("t")
plt.ylabel("Densidade")
plt.grid(True)
plt.legend()
plt.show()
O p-valor é a probabilidade de obter um resultado tão extremo quanto o observado, assumindo que a hipótese nula (H₀) é verdadeira.
Interpretação prática:
p pequeno (p < α): indica que o resultado observado seria muito raro se H₀ fosse verdadeira → Rejeitamos H₀.
p grande (p ≥ α): o resultado é compatível com H₀ → Não rejeitamos H₀.
O p-valor não é a probabilidade de H₀ ser verdadeira – ele mede a força da evidência contra H₀.
from scipy.stats import chisquare
### Exemplo da Aula teoria com a probabilidades de arriscar em uma letra por resposta
observado = np.array([35, 25, 20, 20])
esperado = np.array([25, 25, 25, 25])
chi2, p = chisquare(f_obs=observado, f_exp=esperado)
print(f"Qui-quadrado: {chi2:.2f}, p-valor: {p:.4f}")
if p < 0.05:
print("Rejeitamos H₀: proporções diferentes do esperado")
else:
print("Não rejeitamos H₀")
Qui-quadrado: 6.00, p-valor: 0.1116
Não rejeitamos H₀
Teste Qui-Quadrado de Independência
**Cenário**
Em uma cidade com 1.000.000 de habitantes, foi realizada uma amostra aleatória de 650 residentes. Para cada pessoa, foram registrados:
* **Bairro de residência**: A, B, C ou D
* **Ocupação**: "white collar" (colarinhos brancos), "blue collar" (colarinhos azuis) ou "no collar" (sem colarinho)
A hipótese nula (H₀) é que o bairro de residência é independente da ocupação da pessoa.
A tabela de contingência com os dados observados é:
| Ocupação | Bairro A | Bairro B | Bairro C | Bairro D | Total |
Chi2 = 0.0
for i in range(3): # colunas
for j in range(4): #linhas
#print(i,j,tabela[i][j]-(soma_Ocup[i]*soma_Bairros[j]/tabela.sum()))
aux = tabela[i][j]-(soma_Ocup[i]*soma_Bairros[j]/tabela.sum())
Chi2 = Chi2 + aux**2 /(soma_Ocup[i]*soma_Bairros[j]/tabela.sum())
Chi2
24.5712028585826
import numpy as np
from scipy.stats import chi2_contingency
# Realizando o teste qui-quadrado de independência
chi2, p_valor, dof, esperado = chi2_contingency(tabela)
# Exibindo os resultados
print(f"Estatística qui-quadrado: {chi2:.4f}")
print(f"p-valor: {p_valor:.4f}")
print(f"Graus de liberdade: {dof}")
print("\nFrequências esperadas:")
print(np.round(esperado, 2))
# Interpretação com nível de significância de 5%
alpha = 0.05
if p_valor < alpha:
print("\nRejeitamos H₀: existe associação entre bairro e ocupação.")
else:
print("\nNão rejeitamos H₀: não há evidência de associação entre bairro e ocupação.")
Estatística qui-quadrado: 24.5712
p-valor: 0.0004
Graus de liberdade: 6
Frequências esperadas:
[[ 80.54 80.54 107.38 80.54]
[ 34.85 34.85 46.46 34.85]
[ 34.62 34.62 46.15 34.62]]
Rejeitamos H₀: existe associação entre bairro e ocupação.